1、首先用import 代码引入模块,具体如下:
import re

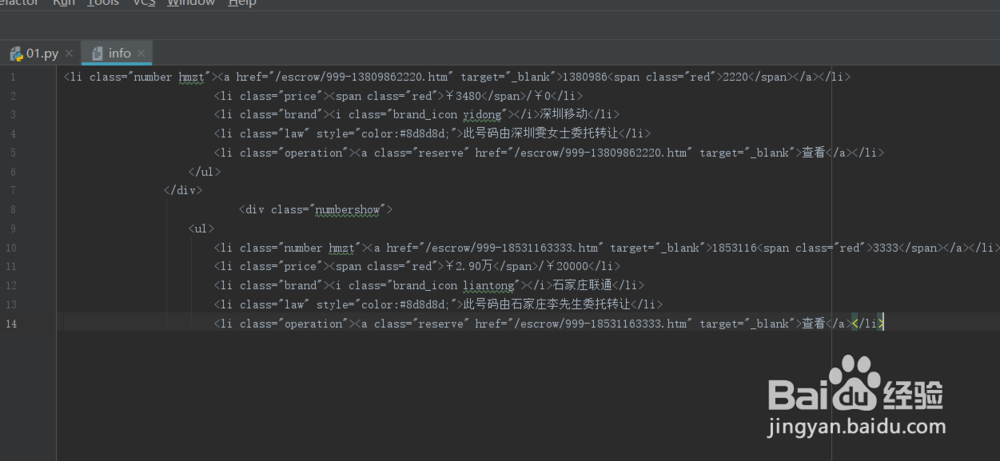
2、接下来准备好我们想要提取的目标文本,我这里是复制了一段html代码,其中包含一些手机号信息
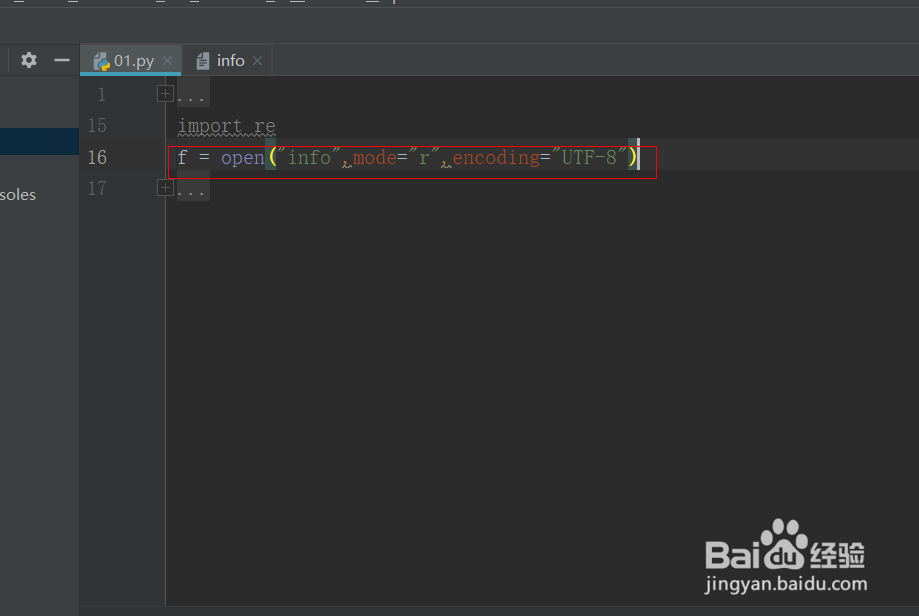
3、建立变量f,用open命令打开它,具体代码如下:
f = open("info",mode="r",encoding="UTF-8")
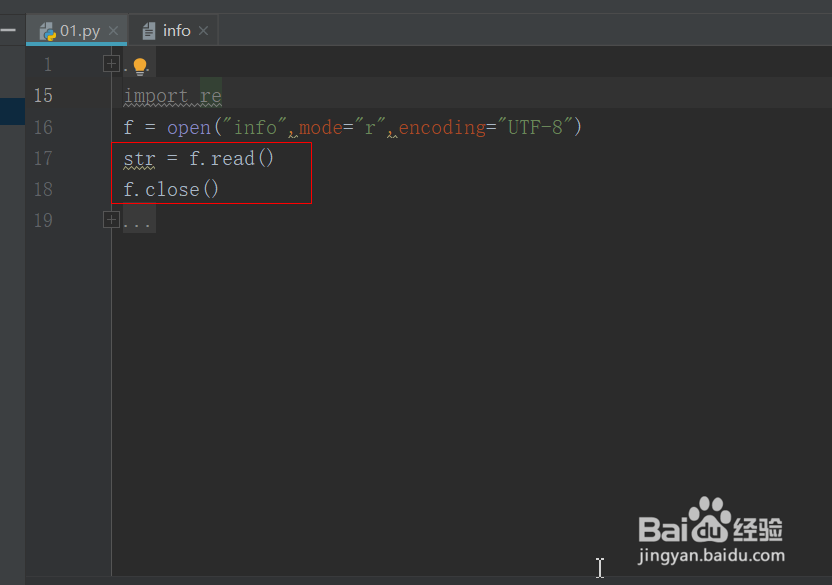
4、建立变量str ,赋值为读取到的文件内容,然后关闭打开的文件。
str = f.read()
f.close()
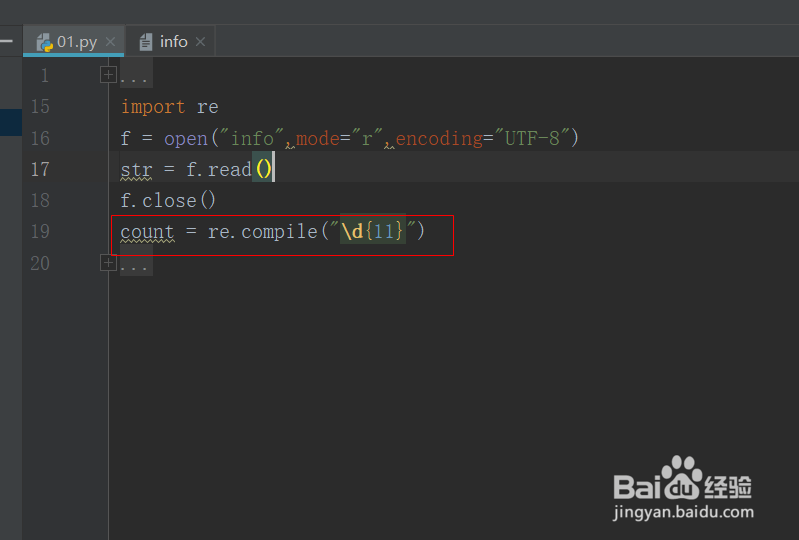
5、接下来我们写最关键的正则表达式部分的内容,由于手机号码都是数字,所以我们这里只用/d 这个正则表达式即可。
count = re.compile("\d{11}")
手机号码都是11位的,所以我们匹配11位的数字
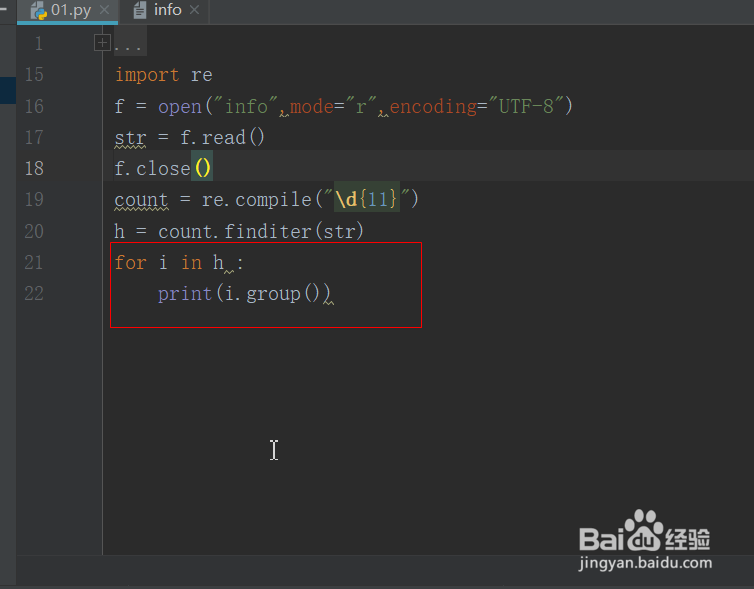
6、最后我们把匹配结果进行一个提取并且打印,具体代码如下:
h = count.finditer(str)
for i in h :
print(i.group())
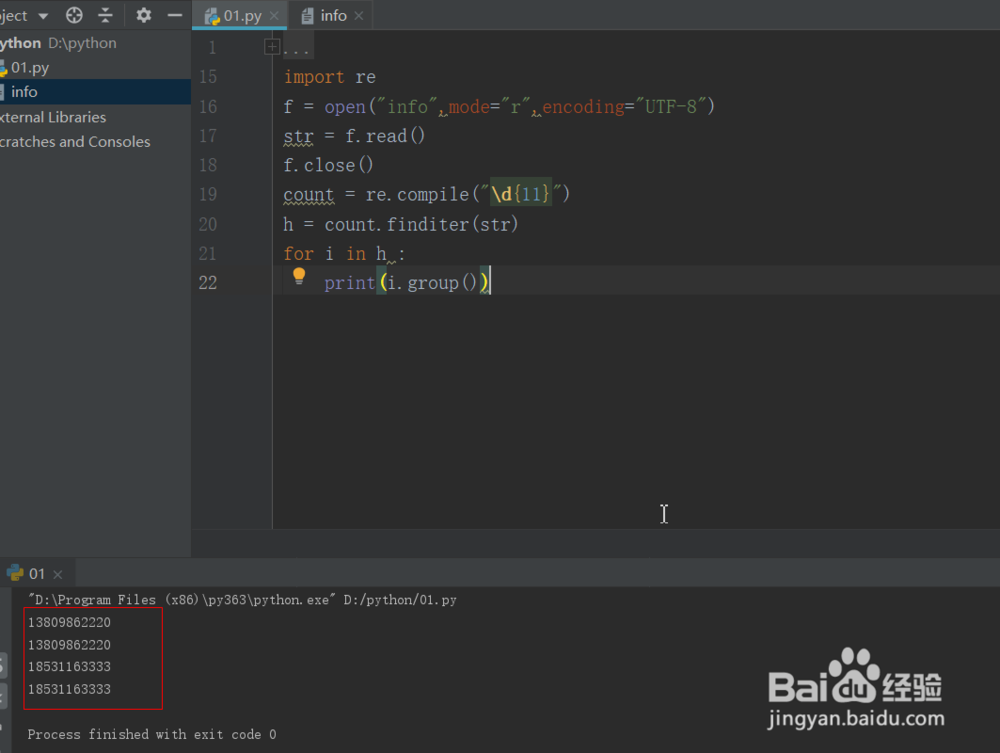
7、代码总结和运行效果:
import re
f = open("info",mode="r",encoding="UTF-8")
str = f.read()
f.close()
count = re.compile("\d{11}")
h = count.finditer(str)
for i in h :
print(i.group())